这篇我们接上一篇把文件操作接着写完,上篇我们介绍了文件的读写,在最后我们了解到了生成一个文件需要用到write()函数,现在我们介绍另一个写入文件的方式, 在shell下我们都知道有个echo命令, 它可以方便的将我们的文本写入或追加到一个文件中,在python下也有类似的方法,如果我们open了一个文件f,用以下语法就可以写入到这个文件中,类似echo命令:
|
1 |
>>> print >>f, 'some strings you want to write' |
这个命令就可以把这个字符串追加到这个文件中,了解了这个方法,我们就可以在我们脚本中,将生成的结果直接重定向到我们的文本中,生成我们要的结果,但这种方法其实还有另一个用法,比如动态生成脚本,就是根据你输入的参数不同,生成的shell脚本也不同,这样可以很灵活的完成不同功能,比如要备份某些台机器的文件,你可以输入源和目的,自动生成一个shell脚本,然后调用去执行:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#!/usr/bin/python env import os import os.path def create_shell(src,des): if os.path.exists('./do.sh'): os.remove('./do.sh') with open('do.sh', 'a') as f: print >>f, '#!/bin/bash' print >>f, 'rsync -avzP {0} 1.1.1.1:{1}/ '.format(src,des ) if __name__ == '__main__': create_shell('/data','/data') |
这个脚本运行完会审生成一个do.sh的脚本文件,内容如下:
|
1 2 |
#!/bin/bash rsync -avzP /data 1.1.1.1:/data/ |
这个脚本是动态生成的,根据你输入的参数不同,生成的脚本内容也不同。
这个内容就介绍到这里,接下来我看看如何读写CSV格式的文件,把结果转成CSV格式这个操作比较常见,下载下来用打开是表格形式,非常方便提供给其它部门或自己分析用,我们先看如何生存一个csv文件,假设你现在有一个数据文件内容如下:
|
1 2 3 4 5 |
cpu, mem, disk 8,16g,200 2,4g,200 4,8g,300 16,32g,600 |
这个可能是你采集的服务器硬件信息, 把这个文件转成csv格式我们需要用到Python的csv模块,上代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#!/usr/bin/env python import csv def csv_writer(data, filename): with open(filename, "wb") as csv_file: writer = csv.writer(csv_file, delimiter=',') for line in data: writer.writerow(line) if __name__ == "__main__": data = [] with open('data.txt') as f: for line in f: data.append(line.strip().split(",")) print data filename = "output.csv" csv_writer(data, filename) |
脚本中我们定义了一个函数负责写入到csv文件, 在主函数中我们先定义了一个data空列表,然后打开我们的数据文件,把数据逗号分隔后加入到列表中,最后调用csv_writer()函数把内容写到文件中,这样就完成了,output.csv文件打开是这样的:
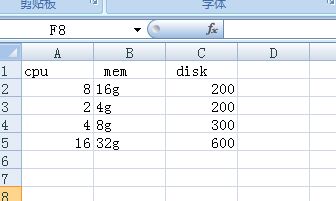
说完写,我们再说读,读一个CSV文件就比较容易了,我们还是用这个Output.csv文件,我们再把它读出来。
|
1 2 3 4 5 6 7 8 9 10 11 |
#/usr/bin/env python import csv def csv_reader(fi): reader = csv.reader(open(fi)) for line in reader: print line if __name__ == "__main__": csv_reader('output.csv') |
结果如下:
|
1 2 3 4 5 |
['cpu', ' mem', ' disk'] ['8', '16g', '200'] ['2', '4g', '200'] ['4', '8g', '300'] ['16', '32g', '600'] |
看读出csv模块以列表的形式展示了我们的结果,根据这个结果其实就可以在脚本中加入自己的逻辑来处理这些数据。
关于CSV文件的操作还有一个比较常用的就是字典写,字典数据结构是非常重要的一种数据结构,所以如果在脚本中我们最终得到的数据是一个字典,那你没必要再转成其他数据结构,直接调用csv的字典写方法就可以写入到一个文件中,我给一个简单的例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#!/usr/bin/env python import csv d = {'a':1, 'b':2,'c':3,'d':4,'f':5} f = open('dict2csv.csv', 'wt') dict_writer = csv.DictWriter(f, fieldnames = d.keys()) dict_writer.writeheader() dict_writer.writerow(d) f.close() |
在脚本中我直接定义了一个字典d,然后到打开一个csv文件, 调用csv.DictWriter()去写入,注意这个函数有2个参数,第一个文件文件对象,第二个是字典的Key, 然后写入头部就是把key写入,然后写入字典的数据,生成的文件结果是这样的:
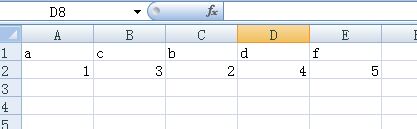
这篇就到这里,喜欢的小伙伴欢迎转发,谢谢