- 管理
- 启动:
Redis-server 或redis-server /etc/redis/redis.conf
- 关闭:
Redis-cli SHUTDOWN 或kill redis进程号
- 安全设置:
Bind 127.0.0.1 #指定只允许本机连接
Requirepass mypassword
>AUTH mypassword
>SET foo
命令重命名:
FLUSHALL #
Rename-command FLUSHALL fuckmemcache
Rename-command FLUSHALL “”
- 管理工具:
Redis-cli
>SLOWLOG GET
Slowlog-log-slower-than 单位是微妙默认是10000, 1000000微妙是1秒
Slowlog-max-len //限制记录的条数
- Phpredisadmin
- 超级管理工具
搜狐出品的管理工具: CacheCloud

- 监控:
命令行:
1、Redis提供的INFO命令不仅能够查看实时的吞吐量(ops/sec),还能看到一些有用的运行时信息。下面用grep过滤出一些比较重要的实时信息,比如已连接的和在阻塞的客户端、已用内存、拒绝连接、实时的tps和数据流量等:
redis-cli -h 127.0.0.1 info | grep -e “connected_clients” -e “blocked_clients” -e “used_memory_human” -e “used_memory_peak_human” -e “rejected_connections” -e “evicted_keys” -e “instantaneous”
2、从客户端可以监控Redis的延迟,利用Redis提供的PING命令,不断PING服务端,记录服务端响应PONG的时间。下面开两个终端,一个监控延迟,一个监视服务端收到的命令:
redis-cli –latency -h 127.0.0.1
3、
>redis-cli -h 127.0.0.1
>monitor
4、unix 命令行
watch -n 1 -d “redis-cli -h 127.0.0.1 info | grep -e “connected_clients” -e “blocked_clients” -e “used_memory_human” -e “used_memory_peak_human” -e “rejected_connections” -e “evicted_keys” -e “instantaneous””
5、图形界面
redis-live
第三方:redis-stat 命令行
压力测试:
redis-benchmark -c 10 -n 100000 -q
原理:
- 持久化
RDB方式:
通过快照完成
Save 900 1 //900秒内有1个键被更改写快照
Save 300 10 //300秒内至少有10个键被就写快照
Save 60 10000 //60秒内有10000键发生变化就写快照
Dump.rdb
配置文件:
Dir //指定快照目录
Dbfilename //指定快照文件名称
快照原理:
Redis进程 fok一个子进程,父进程继续接收处理客服发来的命令,子进程开始讲内存的数据写入硬盘中的临时文件中,写完后用临时文件替换旧的RDB文件。
注意:fork函数发送的一刻父子进程共享同一内存,这时如果父进程要更改其中某片数据,操作系统会将该片数据复制一份以保证子进程的数据不受影响,所以新的RDB文件存储的是执行FORK一刻的内存数据。
Redis重启后会读取rdb 文件,1g快照20~30秒, 如果redis异常退出,就会丢失最后一次快照以后更改的数据,这个要跟进应用场景来定,看可接受的损失范围,如果是做缓存,丢几十个键是没关系的,如果数据相对重要,希望降到最低,就要用AOF方式了。
AOF方式:
Append only file, redis 每执行一条更改redis 数据的命令,就会将该命令写入磁盘中的AOF文件。
Auto-aof-rewrite-percentage 100 //当目前aof文件大小超过上一次重写时的AOF文件大小的百分之多少会再次重写。
Auto-aof-rewrite-min-size 64mb //限制了允许重写的最小AOF文件大小。
操作系统缓存机制,数据先写入了硬盘缓存,默认30秒后再写入磁盘,如果发生故障,这30秒的数据将丢失,如果要开启实时同步需要配置:
Appendsync everysec /always/no no表示不主动同步。
- 主备复制原理
Redis-server //启动主数据库
Redis-server –port 6380 –slveof 127.0.0.1 6379 //启动从数据库

如果断链,2.6版本的会全部再进行复制,2.8以后只会同步增量数据。
从数据库同步过程中,可以继续处理客户端发来的命令,默认从数据库会对同步前的命令做响应,可以配置salve-serve-stale-data no //使从数据库在同步完成前对所有命令都回复错误:SYNC with master in progress.
只要执行复制就会生成快照,即使我们关闭了RDB的方式。
2.8.18之后可以支持无硬盘复制。
Repl-diskless-sync yes //开启无硬盘复制选项
乐观复制:容忍在一定时间内主从数据不一致,但最终数据会同步。

当主数据库执行1条写命令后,主数据库发生变动,当主数据库将该命令传送给从数据库之前,网络断开了,二者数据就不一致了,从这个角度,主数据库是不知道某个命令同步给了多少从数据库,redis提供了2个配置选项来限制只有当数据至少同步给指定数量的从数据库时,主数据库才可写:
Min-slave-to-write 3 //表示只有当3个或以上从数据库连接到主数据库时,主数据库可写。
Min-slave-max-lag 10 //表示允许从数据库最长失去连接的时间。
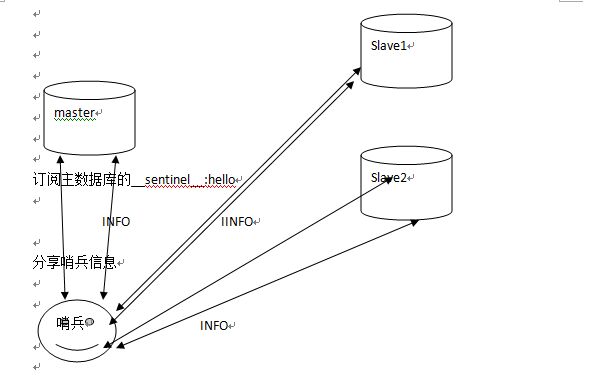
- 哨兵集群原理
2.8版本的功能,功能是监控主从数据库是否正常,主备自动切换
Redis-server //启动主数据库6739端口
Redis-server –port 6380 –slveof 127.0.0.1 6379 //启动从数据库
Redis-server –port 6381 –slveof 127.0.0.1 6379 //启动从数据库
Sentinel.conf
Sentinel monitor mymaster 127.0.0.1 6379 1
其中mymaster是表示要监控的主数据库的名字,ip是主数据库的地址和端口号, 1表示最低通过票数。
Redis-sentinel sentinel.conf
配置监控主数据库,哨兵会自动发现所有从数据库。
Sentinel down-after-milliseconds 60000 或600毫秒
哨兵每秒发送PING命令,如果没回复,哨兵认为主观下线,如果是主数据库,哨兵发送SENTINEL is-master-down-by-addr 命令询问其他哨兵节点以了解他们是否也认为该主数据库主观下线,如果达到指定数量,哨兵认为其客观下线。
故障恢复:
1、发现客观下线的哨兵A,先每个哨兵发送命令,要求对方选自己成为领导哨兵。
2、如果目标哨兵没有选择过其他人,就同意A
3、如果A发现有超过半数且超过quorum参数值的投票,A为领头哨兵。
4、如果多个哨兵参选,就随机再来一轮选举。
哨兵头领选中后,选择优先级最高的从数据库成为主数据库,slave-priority
- 真正的集群部署,3.0版本以上,开启:
Cluster-enabled